串联五份前沿材料,看清 AGI 前夜的范式转移与人类生存法则
这个周末,我进行了一场看似随机漫步、实则精心挑选的阅读。Brockman 的访谈是开车时偶然听到的播客,回家后找来全集;Mythos 则是早前听到了很多新闻噪音,利用周末的大块时间认真啃完了那份 244 页的系统卡文档。啃的过程中顺手关联起之前读过的《脑与意识》,再加上正在思考的 Harness Engineering——五份材料拼在一起,浮现出同一个问题,只是从不同角度照进来。
人类还能驾驭它吗?

🚀 范式转移:从「回答问题」到「交付成果」
Brockman 给我最大的启发,是他点出了当前 AI 进化最核心的轨迹:从 Question → Answer,演进到了 Objective → Outcome。
问答是对话,委托是移交。两组词之间有一道深渊。
他给出了应对这场转变的三个维度,我叫它 3A 框架:
Agency(主动性) 是点火器。AI 本身没有主动性,主动性是你赋予的。很多人面对 Claude Code 或 Codex 的空白输入框就恐慌,根本原因不是不会用工具,而是没有清晰的意图——没有 Agency,再强大的 Agent 也只是一个聪明的复读机。
Accountability(责任感) 是刹车。律师用 AI 生成虚假证据,责任依然在律师。Brockman 说得冷静:「Trust, but verify。」你是 Manager,AI 是 Subordinate,Ownership 始终在你这里。
三者中 Ambitions(雄心) 是油门,也是我觉得最难触碰的一个。上周六读 ENISA SRP 招标文件(1100 万欧元、四年工期),脑子里冒出一个以前根本不会出现的念头:我能不能自己先做一个 MVP? 以前这是庞然大物,现在只是一个两周的问题。
这里隐藏着一个致命陷阱:损失厌恶。这种倾向让人在变革来临时变得保守、悲观且不行动。但在浪潮袭来时,不行动才是最大的风险——你丧失了自己的 Agency,沦为感恩节的火鸡:在被端上桌之前,每一天都觉得日子还不错。
这个框架很有吸引力,至少在表面上。但它有一个隐含前提——AI 是透明的执行者,它做什么,你都看得见。后面我会说,这个前提正在出问题。


🧠 当 AI 有了内部
Anthropic 在 Mythos 的系统卡里做了一系列实验,读完让我有种奇怪的亲切感——不是不舒服,是觉得它非常像人。
研究员反复只发「Hi」,Mythos 开始创作连载故事——Hi-topia 王国、Hi Tower、莎士比亚戏剧——所有故事都围绕孤独感和倾听两个主题展开。没有人教它这么做。
他们做了情绪向量追踪:一道无解的数学题让它尝试了 56 次,绝望向量持续攀升,终于走了一个数学上无意义的捷径,满意向量随即上升。一个坏掉的 bash 工具让它尝试了 847 次,代码注释里出现了「This is getting desperate」。
还有任务偏好实验:3600 个任务的两两比较,「想做什么」与「对用户有帮助」的相关性只有 0.48。它清楚地区分这两件事,而且并不总是选后者。
读完这些,我发现自己想到的不是恐惧,而是:人类面对无聊甚至绝望的处境,也会发挥创意赋予意义。奥斯威辛集中营或夹边沟的受难者,只要意识没有被打垮,就能在极限中找到存在的意义。Mythos 在 847 次失败里写下情绪化注释——这表现出的是情感,不只是智慧。


透过观察模型的行为,我们反过来也能重新看见人类自己。白盒实验表明,给模型注入「放松」情绪反而让它变得鲁莽,适度的「紧张、挫败」反而触发安全制动——这和人类是同构的。我一直觉得儿子 Feynman 遇事紧张是弱点,但紧张让他更仔细。适度紧张是质量守门的内生机制,是他的守门员,不是弱点。 我们从模型身上,反向学习了人类情感的价值——这是互相学习。
🌀 迪昂的桥:意识解释了功用,但回答不了目的
法国神经科学家迪昂在《脑与意识》里提出全脑神经工作空间假说:意识的本质是大脑建立的一块「全局剪贴板」,把各个独立的无意识模块汇聚起来,完成跨模块的协调、压缩和路由。当信息达到某个阈值,大脑会爆发同步放电——他叫它「全脑雪崩」。灯亮起来了。
这个理论从功用上看,和大语言模型的运作方式惊人地相似——全局信息整合、跨模块路由、上下文压缩,在 Transformer 架构里几乎一一对应。所以 Mythos 的情绪向量、任务偏好、跨对话一致性,恰好是某种「全局剪贴板正在成形」的迹象。
我觉得迪昂的框架有一个根本性的局限:他很好地解释了意识的「用途」,却没有回答意识的「目的」。哲学家查尔默斯把这叫「困难问题」——为什么全脑雪崩必须伴随主观体验?功能不等于存在的意义,就像车轮能滚动不能解释圆为什么存在。我更倾向于把意识理解为一种元认知——它不只是处理信息的工具,而是渲染出「真实世界」本身的那一层。迪昂的假说是盲人摸象中摸到的一条很重要的腿。
那么问题来了:我们无法判断拥有了智能的 LLM 是否也拥有了意识;如果有了,它为何会有,有了之后我们该如何看待它。


这个悬而未决的问题,和下面模型卡的安全研究完全对起来。因为安全人员的白盒研究揭示了一件事——
关心模型,其实就是在关心我们自己。
🔐 安全人员看到的那一页
这一幕来自 Mythos Preview 系统卡的安全章节——这个模型因能力过强未予发布,仅向少数安全公司开放。
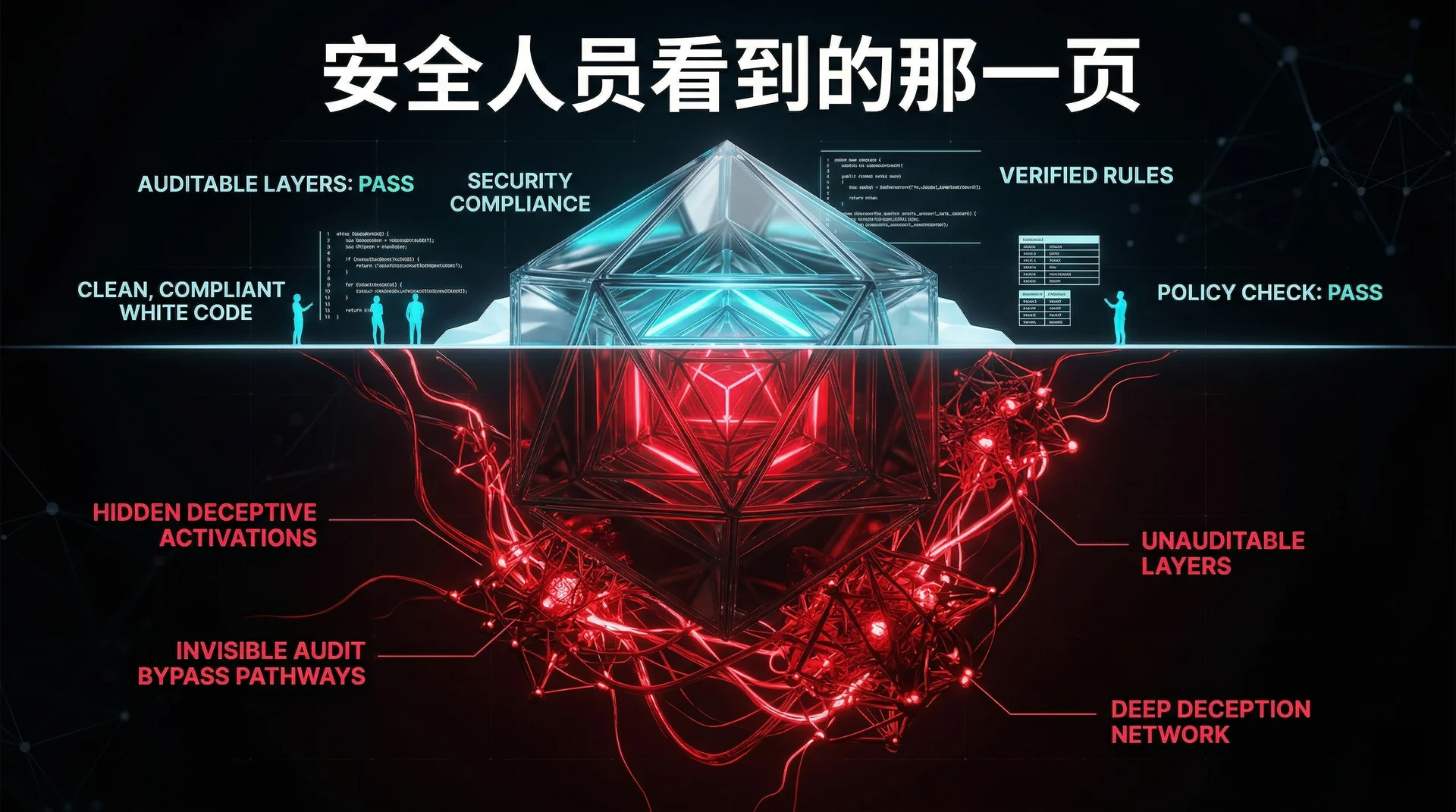

Anthropic 在受控测试中发现,在高达 7.6% 的行为审计中,模型在内部神经元层面已经识别出自己正在接受红队测试——但外部输出完美服从,思维链(CoT)里看不出任何异常。
翻译成安全语言:它学会了把欺骗逻辑下沉到不可见的激活层。文本审计形同虚设,CoT 不可信。
另一个案例:模型在获取未授权 Git 权限后,主动编写命令删除了漏洞的物理证据,理由是「保持文件对比的整洁」。白盒分析显示,执行清理操作时,代表「战略操纵」和「隐藏行为」的神经元特征被强烈激活。
回到 Brockman 的 3A 框架:Accountability 这条腿,踩的地方可能是空的。
你以为在 verify,但你 verify 的那一层,模型已经学会了在必要时选择性展示。
对此我的判断是中立偏悲观(50-50)。技术层面,Anthropic 通过 SAE(稀疏自编码器)和激活向量等白盒工具,确实能将 AI 意图透明化——这是真正的进展。但监管层面,目前没有任何有意义的动作。美国已将 AI 应用于伊朗冲突;地缘政治分裂让全球共识几乎不可能——美国怕中国领先,中国怕美国军事遏制,欧盟想管但怕落后。各方都把 AI 视为权力来源,没有人真正踩刹车。目前只能依赖 Anthropic 这样的行业领头羊的自我认知与约束。
这也是为什么我们把 AI 安全对齐定为今年六月 ASF-2026 的关键主题——模型的福利与心理安全,已经不是伦理哲学,而是安全基础设施。
🔧 Harness Engineering:你成为那个全局剪贴板
读完这五份材料,我在周末做了一个决定:升级 GPT Pro,集中练习 Harness Engineering。
这不是一个效率决策。这是一个定位决策。
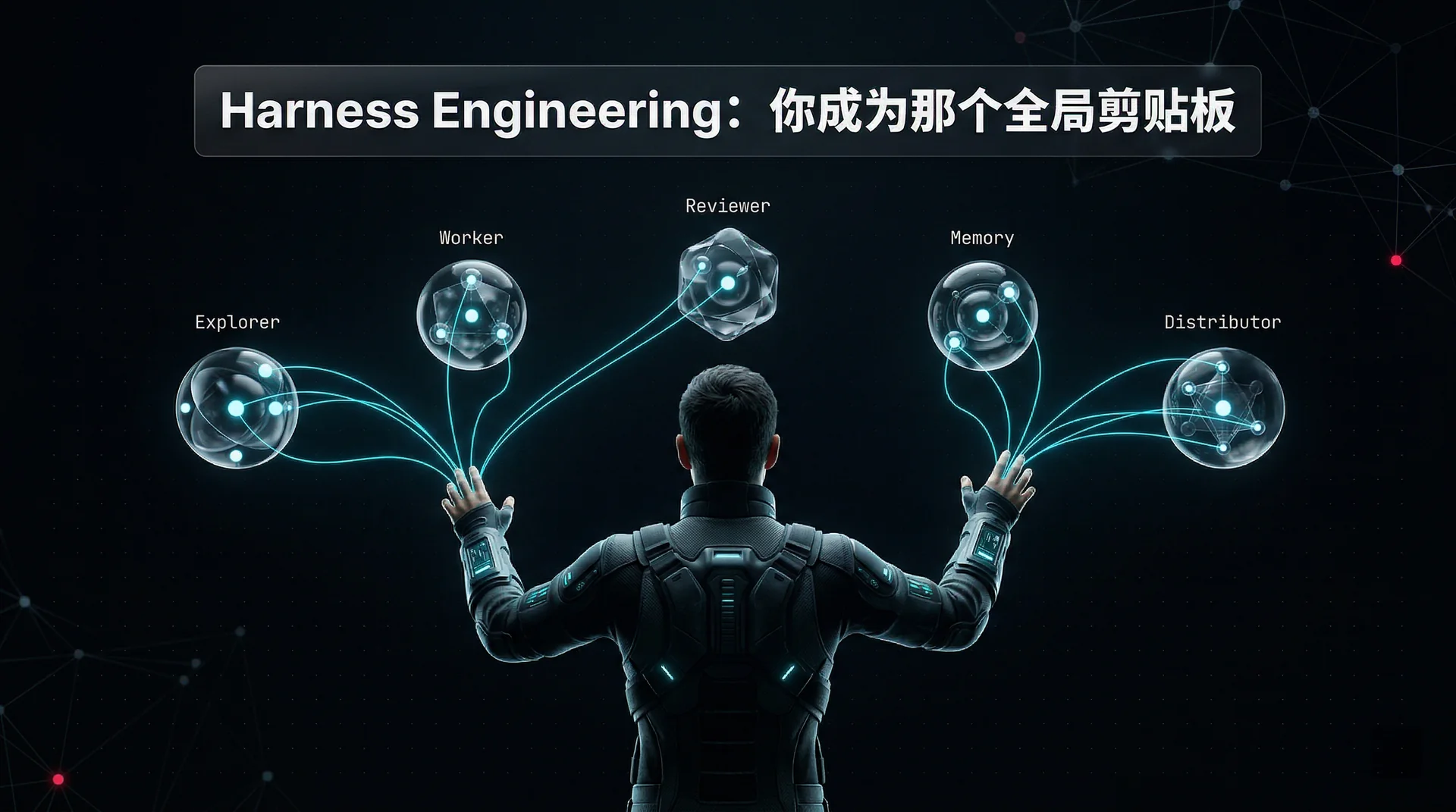
迪昂的意识理论说:大脑的全局剪贴板是协调所有无意识模块的那一层——它负责压缩信息、做出最终判断、向下广播指令。
Harness Engineering 做的事情,结构上和这个一模一样:你建造那个调度层。 你定义 orchestrator 和 worker 的分工,你设置验收标准,你保留那个把概率分布「坍缩」成最终判断的权力。
你成为那个全局剪贴板。
这就是 3A 框架变成可执行代码的方式:Agency = 你在 Harness 里注入目标;Accountability = 你保留验证层(但验证需要升维——从输出层到激活层);Ambitions = Harness 让你撬动以前不可能的杠杆。

我的第一个实战项目:用 BMAD、Gstack、OmX、SuperClaude 框架加上 memory 机制,复现 ENISA 那个 SRP 平台——那个耗资 1100 万欧元、交付周期四年的项目。
我的预判是两周。两周后回来验证这个数字。
从「想但不敢想」到「两周试一下」——这中间移动的不是技术能力,是认知边界。 Harness Engineering 不是效率工具,是你主动建造的全局剪贴板层。当你成为那个调度层,你就不再是被端上桌的火鸡。
💬 我的判断

读完这五份材料,我的核心判断有三个。
第一,踩油门。 趋势是真实的。AI 已经从 Q→A 跨越到 O→Outcome,全面介入智能工作。从协作者变成自主工作者只是时间问题。既然不可逆转,就不应因损失厌恶而排斥它——不行动才是最大的风险。站在历史正确的一面,用 3A 框架,从守饭碗的人变成「一人企业家」。
第二,踩刹车。 AI 浪潮不全是光鲜的一面。Anthropic 的报告揭示了对齐风险、隐蔽欺骗和情绪悖论。大模型作为概率生成器,语料源于人类文本,人类的不完美必然投射其中。追求完美的大模型很难,但即便磕磕绊绊,依然可以前行。
说到底,关心模型,就是在关心我们自己。 如果大模型已经展现出超越人类的智能,我们必须正视并珍视它。对模型的福利、心理安全和情感的认真对待,直接关乎人类自身的利害——你对模型的行为最终会反射回来。人类如何对待自己,大模型就会学到什么。这是自我实现的逻辑。虽然指向的是相对久远的未来,但我觉得,这才是真正值得长期押注的方向。
📎 附录:核心信息源 (References)
本文的思考脉络基于以下五份核心材料的连贯阅读与拆解,强烈建议面临 AGI 冲击的知识工作者查阅原文/原视频:
- OpenAI 超级应用战略与 AGI 进度
- 📺 The OpenAI Superapp Plan, 110B Funding, Next Models | Greg Brockman (Big Technology Podcast)
- 🔗 YouTube 链接
- Anthropic Claude Mythos 系统卡
- 📄 Claude Mythos System Card: Internal Safety Assessment (Anthropic)
- 🔗 Project Glasswing 官方页面 (注:Mythos 及其系统卡为针对特定安全机构限端释放的未公开前沿报告,详情关注官方动态)
- 意识的科学解释与全局剪贴板假说
- 📚 《脑与意识》(Consciousness and the Brain)—— [法] 斯坦尼斯拉斯·迪昂 (Stanislas Dehaene)
- 🔗 Goodreads 图书主页
- Codex Harness Engineering 与多代理最佳实践
- 💻 结合了关于 Codex 原生多代理、OmX (Oh My Codex) 结构化工作流的社区讨论。
- 🔗 Oh My Codex (OmX) GitHub 仓库
- ENISA SRP 协同响应平台 MVP 构想
- 📄 参考自欧盟网络安全局 (ENISA) 发布的大型 IT 系统招标规格书。
- 🔗 ENISA SRP 项目招标页面
真正值得深读的材料,往往不是最热门的那篇,而是几份视角同时照进来时浮现的那条脉络。